
Nhưng giá trị Ŷ được tính như sau:

Từ đây ta có khái niệm mới là activation function nghĩa là hàm dùng để biến đổi đầu ra thành các giá trị ta mong muốn, ví dụ trong bài toán này ta chỉ quan tâm đến giá trị 0 hoặc 1, sigmoid function có thể được chọn là activation function và được định nghĩa như sau


Tiếp theo ta sẽ nhìn vào cost function của Logistic Regression, ta nên phân biệt giữa cost function và loss function.
Loss function tính toán lỗi cho chỉ 1 training sample
Trong khi Cost function là trung bình cộng của tất cả các loss function trong toàn bộ tập training. Bình thường, nếu giá trị trong grouth truth là y và giá trị ta thu được sau sigmoid function là Ŷ, ta có thể nghĩ ngay tới việc tính loss function như sau:
 (1)
(1)https://datascience.stackexchange.com/questions/10188/why-do-cost-functions-use-the-square-error
Nhưng trong thực tế, loss function sẽ được định nghĩa khác.
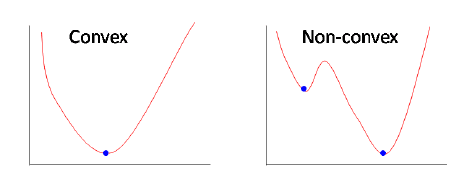
Nhưng vấn đề ở đây ta đang muốn tối ưu hàm L này, và trong bài toán tối ưu, nếu hàm loss là (1), khi đó sẽ có dạng như bên phải hình dưới đây, và là 1 dạng hàm non-convex (hàm không lồi), bởi vì nó sẽ có rất nhiều điểm cực tiểu. Ở trong hình bên phải, điểm cực tiểu là 2 điểm xanh với điểm cao hơn là cực tiêu địa phương (local optima) và điểm thấp là cực tiểu toàn cục (global optima) - là điểm mà ta muốn tìm ứng với giá trị hàm loss là nhỏ nhất.
Với logistic regression, tổng quát lại, ta cần thay đổi các tham số w và b như hình dưới đây để có được giá trị hàm loss là nhỏ nhất.
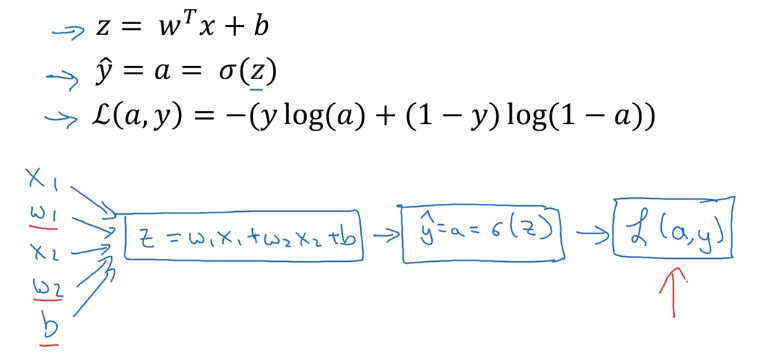
Không có nhận xét nào:
Đăng nhận xét