- Tách từ

- Chuẩn hóa

- Stemming

- Lemmatizing

- Tách câu
NLTK không chỉ hỗ trợ việc tách token trong 1 câu mà còn hỗ trợ việc tách các câu riêng rẽ trong 1 đoạn văn bản. Ví dụ với đoạn văn sau đây:
Khi đó ta không thể dùng text12.split('TOKEN') để tách các câu được vì kết thúc câu có thể là dấu chấm câu, cảm thán, dấu hỏi ... NLTK có bộ tách câu.







- POS tagging
POS tagging là để ta có thể gắn các thành phần trong câu với vai trò tương ứng của chúng ví dụ như chủ ngữ, vị ngữ hay tính từ, tân ngữ ... Tuy nhiên, để gắn nhãn một cách chính xác, ta định nghĩa thêm nhiều vai trò khác ví dụ như mạo từ, liên từ, động từ khuyết thiếu ...
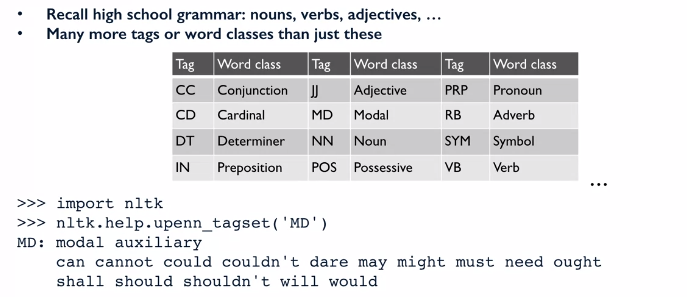
NLTK có bộ POS tagger cho phép ra thực hiện việc này.

Ta có thể thấy từ đầu ra này, ta có thể có các nhóm khác nhau như danh từ, động từ, tính từ ... cho việc xử lý sau đó.
- Parsing Sentence Structure
Khi phân tích cú pháp một câu, ta sẽ luôn có thành phần NP và VP, VP có thể chứa thêm các NP như câu dưới đây, đây là một ví dụ rất đơn giản và cấu trúc dễ phân tích.

NLTK cũng hỗ trợ bộ ChartParser để ta có thể xem được cây cú pháp của 1 câu. Tuy nhiên đôi khi cấu trúc không rõ ràng như sau: I saw the man with a telescope, lúc này này không biết telescope được cầm bởi tôi hay là the man - người đàn ông..

Ta cũng có thể load một cây cú pháp có sẵn và áp dụng vào cho 1 câu.

Tuy nhiên cách làm này không hiệu quả trong thực tế, do đó ta sẽ cần train mô hình để có thể thực hiện việc phân tích cú pháp một cách cụ thể và chính xác.
Không có nhận xét nào:
Đăng nhận xét