- Miscelaneous
Trong các bài toán NN, khi ta đưa đầu vào, thường là các vector, ta cần làm phẳng (flattening out) input. Ví dụ đầu vào là 1 tập 64 ảnh gray size 28x28, khi này input tensor sẽ là (64,1,28,28) với 64 là thể hiện số ảnh. 1 thể hiện độ sáng của ảnh gray từ 0 - 255, ảnh có 28 hàng và 28 cột tương ứng với 784 pixels. Thông thường, với hidden layer ngay cạnh input layer số gồm 784 units ứng với 784 features của input, do đó ta sẽ cần làm phẳng input tensor từ (64,1,28,28) thành (64,784).
Pytorch cung cấp cho ta hàm tối ưu nhất so với torch.reshape và torch.resize đó là torch.view.
Khi dùng torch.view, thay vì ta truyền thẳng các chiều của tensor như. torch.view(64,784), ta chỉ cần dùng torch.view(input.shape[0], -1). Khi này input.shape[0] là 64, và khi tham số thứ 2 là -1, pytorch sẽ tự hiểu là ta muốn reshape với số chiều thứ 2 là tích của các chiều còn lại.
- Train 1 mạng NN
Pytorch cung cấp hàm loss cross-entropy(
nn.CrossEntropyLoss). Đầu vào của hàm này phải là score cho từng class thay vì xác xuất cho từng class khi ta cho đầu ra đi qua hàm soft-max. Ví dụ như sau:
Pytorch cũng hỗ trợ các module cho việc tính toán back-propagation và gradient-descent. Ví dụ ta muốn train một mạng fully-connected NN với 5 epochs cho tập dữ liệu MNIST, hàm loss.backward() sẽ thực hiện đạo hàm, và việc update các ma trận W sẽ được thực hiện bởi optimizer.step().

Khi đó, với 1 sample ngẫu nhiên từ tập dataset, ta có thể dự đoán chính xác.

- Lưu và load 1 mạng NN được train sẵn
Khi mô hình ta đã được train, ta có thể lưu các thông số của mô hình cho các dự đoán tiếp theo mà không cần train lại từ đầu, ta sẽ tìm hiểu cách để lưu và load một pre-trained model trong Pytorch.
Giả sử ta có một class Network trong fc_model, khi đó ta khởi tạo mạng NN như sau:

Cũng trong fc_model, ta gọi method train để tìm ra thông số cho mạng NN này.

Lúc này, tất cả các thông tin của mạng NN được lưu trong model.state_dict() là 1 dictionary. Ta sẽ lưu các thông số này vào 1 file checkpoint.pth sau đó load lại vào state_dict và hiển thị.


 Khi đó, ta cũng có thể tạo 1 hàm dành cho việc load model này.
Khi đó, ta cũng có thể tạo 1 hàm dành cho việc load model này.









Giả sử ta có một class Network trong fc_model, khi đó ta khởi tạo mạng NN như sau:

Ta cũng có thể xây dựng 1 mạng NN mới và thay thế các thông số của mạng đó bằng thông số của mạng NN đã được lưu, khi đó ta tạo 1 mạng mới và load các thông sô.
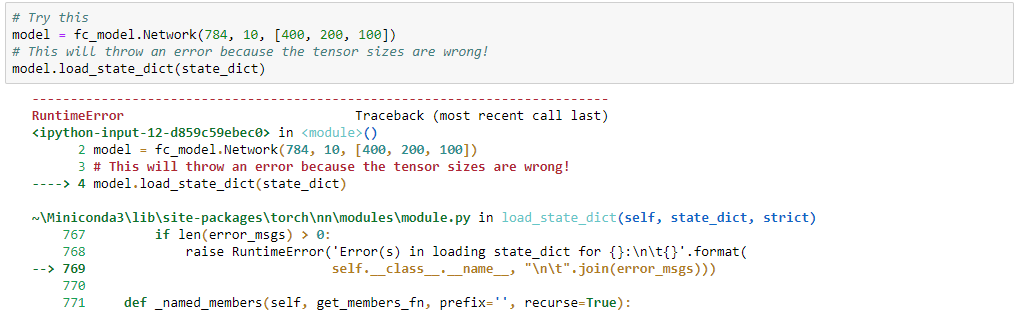
Tuy nhiên ta sẽ có lỗi do size của mạng NN được lưu và mạng NN mới khởi tạo không giống nhau, do đó ở bước thay thế các thông số của mạng mới tạo bằng các thông số của mạng lưu sẵn sẽ xảy ra lỗi.
Để tránh vấn đề này, khi lưu model, ta không chỉ lưu các parameters của model đó (W, b) mà còn nên lưu các hyperparameters bằng cách thêm các hyperparameters này khi ta lưu vào checkpoint.pth.

- Các bước xây dựng 1 mô hình NN trong Pytorch
Đầu tiên ta phải import các thư viện cần thiết của torch, ví dụ:

Tiếp theo ta load input data và preprocess các dữ liệu này.

Tiếp đó ta định nghĩa kiến trúc của mạng NN, ví dụ ta đang muốn sử dụng Transfer Learning dùng DenseNet121, lúc này ta sẽ lấy feature detection part của DenseNet121 là tự xây dựng classification part. Load mô hình DenseNet121 như sau:

Do đang thực hiện Transfer Learning, ta sẽ phải freeze các thông số của feature detection và định nghĩa là classification để thay thế, ví dụ dữ liệu ta đang có chỉ yêu cầu 2 đầu ra, mà dữ liệu của DenseNet là 1000. Sau đó ta cần định nghĩa làm loss và bộ optimizer:

Bây giờ ta đã có kiến trúc mạng như mong muốn, ta có thể train mô hình và sử dụng cho việc dự đoán. Tập dữ liệu là rất lớn do đó việc train mô hình trên GPU sẽ giúp tiết kiếm thời gian rất nhiều.

NOTE:
net.eval() will set all the layers in your model to evaluation mode. This affects layers like dropout layers that turn "off" nodes during training with some probability, but should allow every node to be "on" for evaluation. So, you should set your model to evaluation mode before testing or validating your model, and before, for example, sampling and making predictions about the likely next character in a given sequence. I'll set net.train()` (training mode) only during the training loop.- Operations
Để cộng hoặc trừ hai tensor a và b trong pytorch, ta có thể dùng a + b, torch.add(a,b), toán tử y.add_(x) sẽ trả về y = y + x.
Mọi toán tử giữa hai tensor mà có hậu tố _ như x.copy_(y hoặc x.t_() đều sẽ thay đổi giá trị x.
Khi tensor của ta chỉ có 1 phần tử, ta cần sử dụng .item() để có thể lấy giá trị trị của tensor đó.
>>> x = torch.rand(1)
>>> print(x)
tensor([0.1541])
>>> x.item()
0.15414464473724365
Pytorch cung cấp cho ta các toán tử hầu như giống hệt numpy, và ta còn có thể chuyển đổi kiểu dữ liệu từ numpy sang tensor và ngược lại.
>>> a = torch.ones(5)
>>> a
tensor([1., 1., 1., 1., 1.])
>>> b = a.numpy()
>>> b
array([1., 1., 1., 1., 1.], dtype=float32)
>>> a = torch.from_numpy(b)
>>> a
tensor([2., 2., 2., 2., 2.])
Mọi loại tensors trên CPU ngoại trừ CharTensor đều hỗ trợ việc chuyển đổi sang numpy và ngược lại.
- CNN trong Pytorch
Trong phân loại ảnh, CIFAR-10 là một tập dữ liệu nổi tiếng và thường thấy để kiểm chứng 1 mô hình. Một số hình ảnh của CIFAR-10 như sau:

Khác với MLP (Multi Layer Perceptron) khi ta sử dụng các linear và fully-connected layers, trong một CNN sẽ bao gồm.
- Convolutional layers: Là tập hợp của các bộ lọc ảnh (image filters) liên tiếp nhau ví dụ.

trong hình trên, 4 bộ lọc khác nhau tạ ra 4 ảnh đầu ra khác nhau, khi ta stack các ảnh này lại, ta tạo ra được một convolutional layer với chiều sâu (depth) là 4.

- Maxpooling layers để giảm kích thước của đầu vào, lúc này ta chỉ giữ lại các giá trị quan trọng nhất trong một cửa sổ. Ví dụ của số là 2x2 với 4 pixel, ta sẽ chỉ lấy 1 giá trị pixel quan trọng nhất, do đó chiều x và y của ảnh sẽ được giảm đi 2 lần với mỗi chiều.
- Linear và Dropout layers để tránh overfitting và sinh ra output.
- Convolutional Layer trong Pytorch
Ta định nghĩa 1 convolutional layer như sau:
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0)
trong forward, ta sử dụng layer này để xử lý input:
x = F.relu(self.conv1(x))
Giải thích các đầu vào như sau:
in_channels- Chiều sâu của dữ liệu đầu vào, ví dụ với ảnh RGB, depth = 3 và ảnh gray thì depth = 1out_channels- Số filters mà ta muốn áp dụng vào ảnh đầu vào, với số filter là K này, đầu ra của ta sẽ là K ảnh.kernel_size- Chiều dài = chiều rộng của convolutional kernel (hay filter)
Ngoài ra còn 1 số tham số khác
stride- Chiều dài trượt của kernel,strideđược set mặc định là1padding- Chiều dài ta muốn thêm vào ảnh ở đường biên, mặc địnhpaddingđược set là0.
Ngoài ra còn Pooling layer để ta có thể giảm kích thước của ảnh đầu ra sau 1 convolutional layer (tránh overfitting).
self.pool = nn.MaxPool2d(2,2)
Ở đây kernel_size = 2 và stride = 2. Ở trong hàm forward(), hàm pooling được sử dụng sau conv layer.
x = F.relu(self.conv1(x))
x = self.pool(x)
Ví dụ: Ta xây dựng 1 CNN, đầu vào là ảnh gray có kích thước 200x200 do đó nó là 1 mảng 3 chiều có chiều dài 200, rộng 200 và sâu 1.
self.conv1 = nn.Conv2d(1, 16, 2, stride=2)
Đầu vào này được xử lý bởi 16 filters, mỗi filter có chiều dài là 2 và rộng là 2, độ trượt stride = 2 và ta không muốn thêm padding vào đầu input.
Tiếp theo, đầu ra của conv1 sẽ là 16 ảnh khác nhau sau khi đi qua 16 filters. Ta định nghĩa 1 conv kế tiếp có 32 filters có chiều dài và rộng là 3, độ trượt stride = 1 và padding 1 vào đường biên.
self.conv2 = nn.Conv2d(16, 32, 3, padding=1)
Ta có thể thấy đầu vào của conv2 chính là depth của đầu ra sau conv1, vì conv1 có 16 filters nên depth sẽ cũng chính là 16.
Tiếp theo ta sẽ tìm hiểu cách tính toán size của 1 ảnh sau khi qua 1 conv layer.
Ta định nghĩa.
K- Số filter của 1 conv layerF- Chiều dài và rộng của 1filterD_in- Depth của layer trước đó, ví dụ layer trước đó là input thì depth là 3 hoặc 1 tương đương với ảnh RGB hay gray. Hoặc là 16 với ví dụ trên khi ta đang xét conv2.
Do vậy, số lượng tham số của 1 filter là F*F*D_in và ta có K filters, do đó số lượng weight sẽ là K*F*F*D_in.
Ta nhắc lại một số định nghĩa và thêm một số khác.
K- Số filter của 1 conv layerF- Chiều dài và rộng của 1filterS- Độ trượt của kernelP- PaddingW_in- Là D_in, depth của layer trước đó, ví dụ layer trước đó là input thì depth là 3 hoặc 1 tương đương với ảnh RGB hay gray. Hoặc là 16 với ví dụ trên khi ta đang xét conv2.
Ta lưu ý rằng depth của 1 conv layer sẽ luôn là số lượng filter K.
Khi đó, size của 1 ảnh khi đi qua 1 conv layer được tính là:
((W_in−F+2P)/S)+1 (*)
Ta thử làm một bài toán, dưới với ảnh đầu vào có size là 130x130 và có depth là 3 ứng với ảnh RGB.
nn.Conv2d(3, 10, 3) <--- conv1
nn.MaxPool2d(4, 4) <- maxpool1
nn.Conv2d(10, 20, 5, padding=2) <---- conv2
nn.MaxPool2d(2, 2) <- maxpool2
Khi này depth của output sẽ là depth của conv2 là 20.
Đầu tiên dựa vào công thức (*) ta có size của ảnh sau khi qua conv1.
Với conv1:
W_in = 130
F = 3
P = 0
S = 1 (by default if not specified)
W_out_conv1 = ((130-3+2x0)/1) +1 = 128 (size 128x128)
Khi qua maxpool1, size ảnh sẽ là 128/4 = 32 (size 32x32)
Với conv2:
W_in = 32
F = 5
P = 2
S = 1
W_out_con2 = ((32-5+2x2)/1) +1 = 32 (size 32x32)
Khi qua maxpool2, size ảnh là 32/2 = 16 (size 16x16)
Khi này, output cuối cùng sẽ là 20*16*16
- Data Augmentation
Khi ta train một mô hình phức tạp, gồm nhiều thông số trong mạng cần tìm, số lượng dữ liệu cần thiết là rất lớn. Do vậy, nếu số lượng dữ liệu của ta không đủ lớn, ta có thể làm gì? Trong thực tế việc tìm kiếm thêm dữ liệu đôi khi không cần thiết, ví dụ như trong ảnh dưới đây, 1 mạng neuron chưa được train tốt sẽ không phân biệt được 3 ảnh này là giống nhau.

Do đó, nếu ta muốn có thêm dữ liệu, ta chỉ cần sửa đổi một chút dữ liệu sẵn có ví dụ như ta đảo chiều ảnh, xoay ảnh hay dịch ảnh, khi đó mạng NN sẽ có thể được train tốt hơn. Kỹ thuật này được gọi là Data Augmentation như minh họa dưới đây.

Các kỹ thuật ta có thể làm bao gồm:
- Flip

Lật ảnh theo chiều dọc hoặc ngang
- Rotation

Xoay 90 độ theo chiều kim đồng hồ
- Scale/Crop

Ảnh đã được scale in 10 và 20%
- Translation

Ảnh dược dịch qua phải là dịch lên trên
- Gaussian Noise

Thêm nhiễu Gaussian
Ngoài ra còn một số kỹ thuật nâng cao khác như GAN, Style transfer, ta có thể đọc thêm từ đây.
https://medium.com/nanonets/how-to-use-deep-learning-when-you-have-limited-data-part-2-data-augmentation-c26971dc8ced
Trong Pytorch, toán tử transforms được dùng để ta có thể thực hiện data augmentation một cách cơ bản như xoay ảnh và lật ảnh, scale/crop.
Không có nhận xét nào:
Đăng nhận xét