- Pre-seeding > Seeding > A > B > C > ....
- A seed funding round is all that the founders feel is necessary in order to successfully get their company off the ground; these companies may never engage in a Series A round of funding.
- How to get the final product? All money that I need to reach the final product
+ Hiring people (How many people, company size?)
+ Office
+ Networking; dining
+ Equipment
+ Marketing (later)
+ Website
+ Paperwork
Thứ Ba, 28 tháng 4, 2020
Thứ Tư, 22 tháng 4, 2020
[Review sách] Những người đàn ông không có đàn bà - Haruki Murakami - by harukipedia
- Lái xe/cô gái không nói nhưng hút thuốc nhiều
- Yesterday/nhân viên làm sushi
- Scheherazade/Habara
- Cá mút đá ăn hương
- Những câu truyện trong bụng mẹ
- Đột nhập ở tuổi 14
- Cô gái gù ở Praha/cuộc bạo loạn và nắm cửa bị hỏng
- Quán bar góc phố/rắn/cây liễu và đi đừng dừng lại
- Yesterday/nhân viên làm sushi
- Scheherazade/Habara
- Cá mút đá ăn hương
- Những câu truyện trong bụng mẹ
- Đột nhập ở tuổi 14
- Cô gái gù ở Praha/cuộc bạo loạn và nắm cửa bị hỏng
- Quán bar góc phố/rắn/cây liễu và đi đừng dừng lại
[Review sách] Biên niên sử chim vặn dây cót - Haruki Murakami - by harukipedia
Toru Okada
Chim không bay
Giếng không nước và thang dây
Một người vợ bỏ đi - Kumiko
Tiệm giặt là
Chiếc váy màu xanh dương nhạt
Kano Malta/Creta
Đi xuyên qua tường
Vết thâm trên mặt
Chiến tranh nội Mông giữa Nhật vs Liên Xô (ctr Nga-Nhật lần 2)
Xem mặt thiên hạ giữa phố đông
Thứ Bảy, 18 tháng 4, 2020
Crime vocabularies for IELTS writing
- punishment/castigation (uncountable)/chastisement (uncountable)/deterrent: hình phạt
- Capital punishment/Death penalty: tử hình
- Crime rate: tỉ lệ phạm tội “The reduction of the crime rate is the main goal for lawmakers.
- To commit a crime: phạm tội
- Prison sentence: Hình phạt tù
- A criminal record:
- Loss of freedom: Mất tự do “Loss of freedom is a punishment that offenders have to face when they go to jail.”
- White-collar crime: Crimes committed by “office works”, for example, fraud.
- Be put on probation: Bị đặt dưới sự quản chế. “Sometimes first-time offenders are not imprisoned but are put on probation for a set period of time to ensure their good behaviour.”
- Social isolation: Cách ly khỏi xã hội
- A violent criminal
- Criminals/offenders/wrongdoers/lawbreakers/convicts/felon
- First-time offenders
- Motive for crime: Động cơ phạm tội. ” A desire for revenge on his wife is a motive for his crime as murder. “
- Turn to a career of crime: trở thành tội phạm
- To be imprisoned: Bị bỏ tù
- Easy money: tiền pham pháp
- Break the law/Engage in unlawful activities/illegal activities: làm điều phạm pháp
- To resort a crime: phạm tội vì bước đường cùng. “After losing all money from the game, the men resorted to crime to get easy money.”
- Soaring crime rates: tỉ lệ tội phạm gia tăng
- To re-offend: Tái phạm tội
- Rehabilitated prisoners: Tội phạm hòa lương
- To send sbd to prison/To put sbd in jail
- Capital punishment/Death penalty: tử hình
- Crime rate: tỉ lệ phạm tội “The reduction of the crime rate is the main goal for lawmakers.
- To commit a crime: phạm tội
- Prison sentence: Hình phạt tù
- A criminal record:
- Loss of freedom: Mất tự do “Loss of freedom is a punishment that offenders have to face when they go to jail.”
- White-collar crime: Crimes committed by “office works”, for example, fraud.
- Be put on probation: Bị đặt dưới sự quản chế. “Sometimes first-time offenders are not imprisoned but are put on probation for a set period of time to ensure their good behaviour.”
- Social isolation: Cách ly khỏi xã hội
- A violent criminal
- Criminals/offenders/wrongdoers/lawbreakers/convicts/felon
- First-time offenders
- Motive for crime: Động cơ phạm tội. ” A desire for revenge on his wife is a motive for his crime as murder. “
- Turn to a career of crime: trở thành tội phạm
- To be imprisoned: Bị bỏ tù
- Easy money: tiền pham pháp
- Break the law/Engage in unlawful activities/illegal activities: làm điều phạm pháp
- To resort a crime: phạm tội vì bước đường cùng. “After losing all money from the game, the men resorted to crime to get easy money.”
- Soaring crime rates: tỉ lệ tội phạm gia tăng
- To re-offend: Tái phạm tội
- Rehabilitated prisoners: Tội phạm hòa lương
- To send sbd to prison/To put sbd in jail
Tourism vocabularies in IELTS writing
- travel abroad/wish to travel/go travelling
- wanderlust: a strong desire to travel
- travel agency
- holiday destination
- dream holiday/holiday of a lifetime
- go on/take a holiday
- excursion: a short journey or trip usually made for pleasure
- go on/make an excursion
- arrange/organize an excursion/an excursion to somewhere
- layover: a stopping place on a journey: a layover in (somewhere)
- accommodation
- breathtaking view: a beautiful view = spectacular landscapes
- go sightseeing
- itinerary: a planned journey or route of a person's travel
- tourist trap: a place where many tourist visit
- impair the local environment: Many tourists throw rubbish into the water, which can significantly impair the local environment
- spend quality time with family and friends
- affordable destinations/travel
- do as the locals do
- around the world
- exotic destination: not a tourist trap
Thứ Năm, 16 tháng 4, 2020
Education vocabularies in IELTS writing
- vocational training: đào tạo nghề
- enter university = go to university = enroll in college = register for college = vào trường ĐH
- get/achieve/obtain/acquire higher academic results = đạt kqua học tập tốt hơn
- extracurricular/outdoor activities = hoạt động ngoại khóa
- perceive/learn a wide range of skills = học được nhiều kỹ năng
- a reservoir of knowledge = một bể kiến thức
- encourage/stimulate independent learning = khuyến khích tự học
- apathetic parents = cha mẹ vô tâm / parent apathy: sự vô tâm của cha mẹ
- improve educational outcomes = cải thiện đầu ra cho giáo dục
- theoretical knowledge >< practical/working experience
- To pursue tertiary education/To access to tertiary education: Tiếp cận giáo dục đại học
- To offer students comprehensive education/To provide students with ...: cung cấp GD toàn diện
- To obtain/possess formal qualifications: Đạt được bằng cấp đại học
- A knowledge-based society/economy: Xã hội/nền KT dựa trên kiến thức
- To open the door to better career prospects: Mở rộng cơ hội nghề nghiệp
- To give favorable conditions to do STH
- To facilitate online/distance learning: Tạo điều kiện học tập từ xa
- To integrate technology into classroom learning = Tích hợp công nghệ vào học tập
- matriculants/matriculation: người trúng tuyển/sự trúng tuyển: thousands of matriculants gain access to higher education
Chủ Nhật, 12 tháng 4, 2020
The shits always confound me in GRE quant
- Intergers
- factor hay divisor của 1 số là các số cấu thành nên số đó từ phép nhân. Ví dụ 1 2 4 5 10 và các giá trị âm tương ứng là các factors của 20
- 20 là divisible bởi từng factor của nó
- multiple: multiple của 1 số x là các số nguyên có dạng n.x với. Ví dụ 20 là multiple của từng factor/divisor của nó. Multiple của 20 là các số 20, 40, 60, 80 v.v...
- 1 là multiple của chính nó và -1
- prime number là các số nguyên chỉ chia hết cho nó và 1 nghĩa là factor của 1 số prime x là x -x 1 -1. Số prime là các số nguyên dương >= 2
- 0 là multiple của tất cả các số, và 0 là factor của duy nhất chính nó
- Least common multiple của 2 số dương không âm là multiple nhỏ nhất của 2 số đó. Ví dụ LCM của 3 và 4 là 12.
- The greatest common factor (divisor) của hai số dương không âm đó là số lớn nhất mà là factor của cả 2 số. Ví dụ 12 và 15 thì the greatest common factor của chúng là 3.
- Không một phép chia không chia hết ví dụ số c chia bởi d (d không phải là 1 divisor của c), khi đó quotient là phần nguyên và remainder là phần dư. Ví dụ 13/5 thì quotient là 2 là 3 là remainder.
- Ta lưu ý rằng remainder luôn lớn hơn hoặc bằng 0, do đó trong phép chia của số âm ví dụ -25/3 thì quotient là -9 và remainder là 2.
- Prime factorization: Là khi ta sử dụng các factor là số prime (prime factor) để biểu diễn 1 số nguyên lớn hơn 1. ví dụ 12 = 2.2.3 = (2)^2.3
- Các số dương lớn hơn 1 mà không phải số nguyên tố gọi là hợp số (not prime number => composite number). Ví dụ như 4 6 8 9 10 12 14 15 16 18
- số 0 được gọi là neutral integer, không phải nguyên âm cũng ko phải nguyên dương
- Fractions
- Là số có dạng c/d (phân số) trong đó c là numerator và d gọi là denominator
- mixed numbers là số có dạng cả nguyên và fraction ví dụ 8(1/2)
- nghịch đảo phân số reciprocal
- square root: căn bậc 2, cube root: căn bậc 3, fourth root: căn bậc 4
- Decimal
- 1 số thập phân phải terminate ví dụ 0.25 hoặc repeat ví dụ như số (1/3)=0.33333... Ngoài ra nếu 1 số thập phân k terminate cũng k repeat được gọi là irrational number.
- Triangle inequality: |s+t| < |s| + |t|
Thứ Bảy, 11 tháng 4, 2020
Em Cún
- Thích daisy
- Thích màu trắng đen
- Thích dream pop: maybe
- Thích uống trà đào có mấy lát quả bên trong
- Thích ăn dưa hấu
- Thích ngủ
- Thích ngủ
- Ngủ hình con tôm quay lưng vào tường
- Dành nhiều thời gian xem phim và nghe nhạc, đọc Hoa Tư Dẫn và Zelda
- Thích vanilla sky, thích ngồi quán coffe rooftop nào đó và kem bơ, có thích 1 quán gần Thủ Đức
- Thịt ăn thịt bò (. ❛ ᴗ ❛.)
Thứ Tư, 8 tháng 4, 2020
Lý thuyết thông tin trong Deep Learning
- Lý thuyết thông tin
Lý thuyết thông tin tính toán lượng thông tin có mặt trong một tập sự kiện. Lượng thông tin này bị ảnh hưởng trực tiếp từ tính khả đoán được của sự kiện (Predictability).
Vậy Predictability là gì?
- Sự kiện mà ta đoán trước được kết quả sẽ không mang thông tin (zero information)
- Sự kiện có ít biến cố mang ít thông tin: ví dụ như tung đồng xu chọn mặt úp hay ngửa
- Những sự kiện ngẫu nhiên mang nhiều thông tin
In information theory, chaos processes more informationThông tin của 1 sự kiện được định nghĩa bằng công thức.
I(x)=−log(P(x))
- Entropy
Trong lý thuyết thông tin, entropy là đại lượng được dùng để tính toán lượng thông tin của 1 sự kiện.
Ta định nghĩa entropy là:
H(x)=Ex∼P[I(x)]
E là kỳ vọng của 1 biến cố (https://en.wikipedia.org/wiki/Expected_value)
Thay I(x) ở trên vào ta được entropy của 1 sự kiện được tính như sau:
H(x)H(x)=−Ex∼P[logP(x)]=−∑xP(x)logP(x)
Nếu log có base là 2 thì H(x) đang tính toán số bit cần thiết để mã hóa 1 thông tin. Trong information theory, lượng thông tin và độ ngẫu nhiên của sự kiện tương quan với nhau (positively correlated). Giá trị entropy cao tương đương với độ ngẫu nhiên cao và ta cần nhiều bit để mã hóa.
- Ví dụ
Để tính toán entropy của việc tung đồng xu (với điều kiện đồng xu là tiêu chuẩn).
H(X)=−p(head)⋅log2(p(head))−p(tail)⋅log2(p(tail))=−log212=1
Do đó ta sẽ chỉ cần 1 bit để thể hiện tập biến cố của phép thử này 0/1.
Ngoài ra, lượng thông tin là lớn nhất khi và chỉ khi p(head) = p(tail) = 0.5
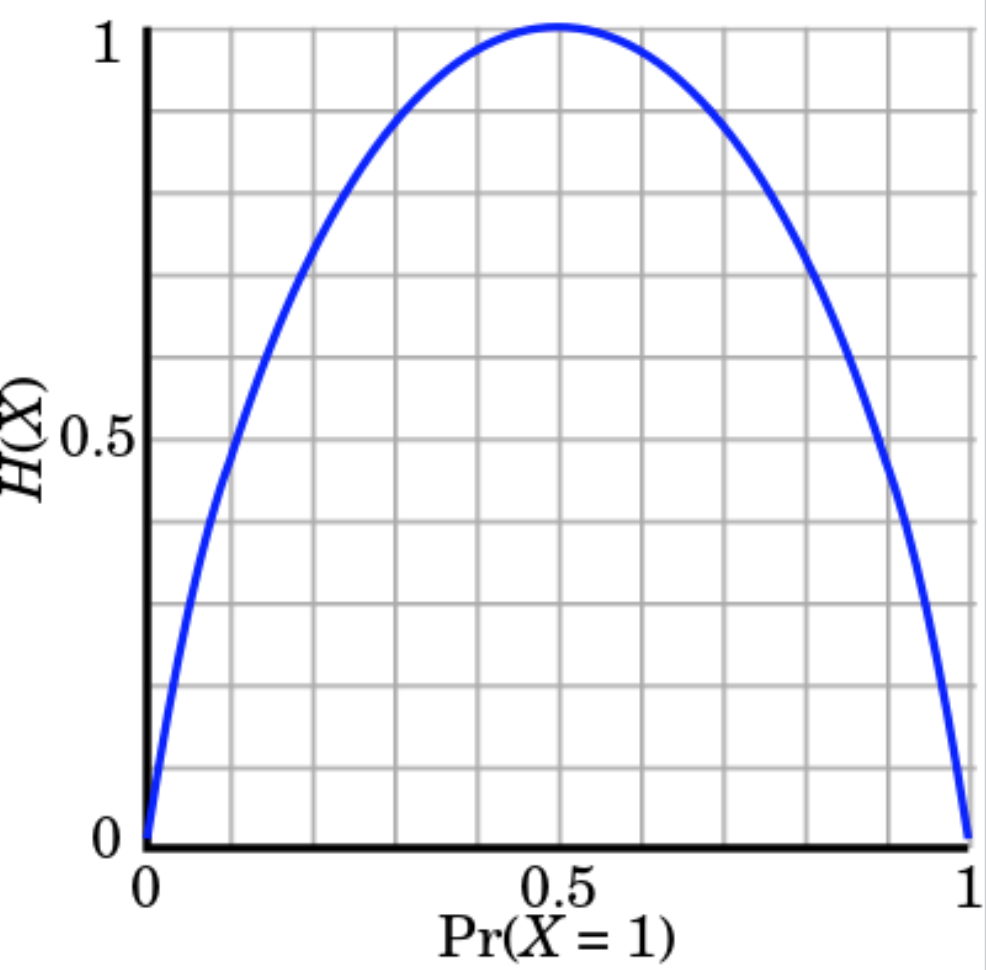
Với 1 con xúc sắc lập phương, entropy là H(X)=
log26≈2.59
Con xúc sắc có entropy cao hơn đồng xu bởi biến độ khó đoán định hơn (less predictable)
- Cross Entropy
Nếu entropy tính toán lượng bit nhỏ nhất để mã hóa thông tin cho trước, cross entropy được sử dụng để tính toán số bit tối ưu để mã hóa phân phối P khi ta sử dụng phân phối Q.
Dễ hiểu hơn, ta có thể coi P là ground truth và Q là prediction. Do vậy hàm loss của ta cũng chính là số bit tối ưu để có thể match hai phôn phối này lại với nhau.
H(P,Q)=−∑xP(x)logQ(x)
In deep learning, P is distribution of the true labels, and Q is the prob. distribution of predictions from the deep network.
- KL Divergence
Trong Deep Learning, ta muốn xây dựng một model để mô hình phân phối Q từ phân phối P của data đã cho trước (training data). Sự khác nhau giữa hai phân phối P và Q có thể được tính toán bằng KL Divergence như sau.
DKL(P||Q)=ExlogP(x)Q(x)
Ta được:
DKL(P||Q)=∑x=1NP(x)logP(x)Q(x)=∑x=1NP(x)[logP(x)−logQ(x)]
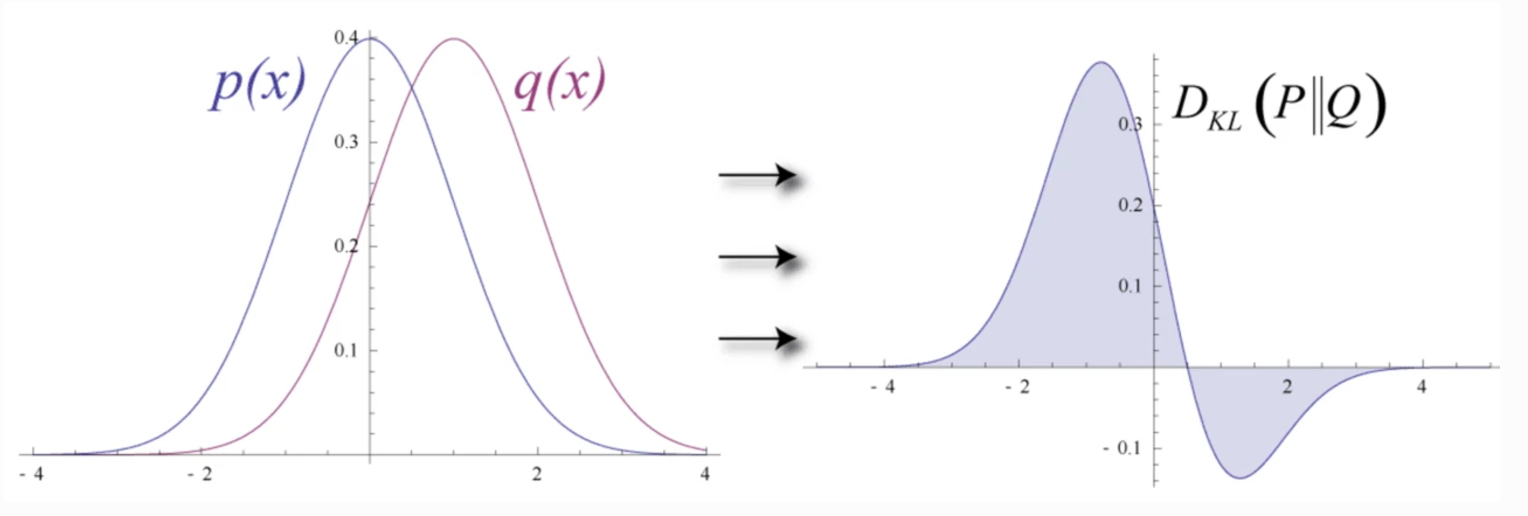
Tuy nhiên ta có thể thấy KL Divergence là không đối xứng. D(P||Q) != D(Q||P)
Và ta có:
H(P)H(P,Q)DKL(P||Q)=−∑PlogP, - entropy=−∑PlogQ, - cross entropy và=∑PlogPQ. - KL divergence
Do đó ta có thể viết lại cross-entropy như sau:
H(P,Q)H(P,Q)=−∑PlogQ=−∑PlogP+∑PlogP−∑PlogQ=H(P)+∑PlogPQ=H(P)+DKL(P||Q)
Hay cross entropy = KL + entropy
Cross entropy H(P,Q) lớn hơn entropy H(P) do ta cần nhiều bit hơn để có thể mã hóa dữ liệu với Q (P khác Q). Do đó, ta có thể chứng minh rằng, KL-div luôn dương khi P khác Q và bằng 0 khi P = Q.
Từ đây, ta thấy rằng KL-div có thể dùng để tính sự sai khác (discrepancy) giữa 2 distribution.
Ta lại có H(P) chỉ phụ thuộc vào phân phối ta đang có, ví dụ tung đồng xu thì H(P) = 1. H(P) không bị ảnh hưởng bởi model ta xây dựng, do vậy, tối ưu giá trị cross entropy tương đương với việc tối ưu KL-div.
lo
H(P,Qθ)∇θH(P,Qθ)=H(P)+DKL(P||Qθ)=∇θ(H(P)+DKL(P||Qθ))=∇θDKL(P||Qθ)
- Maximum Likelihood Estimation
Ta muốn xây dựng một mô hình để cực đại hóa giá trị xác suất của 1 biến cho trước - Maximum Likelihood Estimation or MLE (ví dụ trong training set ta có điểm dữ liệu x, do đó xác suất xuất hiện thưc tế của điểm này là 1) - hoặc nói cách khác mô hình của ta khớp với dữ liệu nhất có thể.
θ^=argmaxθ∏i=1Np(xi|θ)
Nhưng việc nhân các giá trị như trên có thể dễ dàng dẫn đến việc tràn số (overflow) hoặc underflow. Do đó ta chuyển công thức trên về dạng log để tránh vấn đề này.
Tuy nhiên, các optimizer thông thường sẽ chỉ hỗ trợ việc minimize một hàm loss cho trước. Do vậy thay vì tối ưu trực tiếp trên MLE, ta áp dụng log và tối ưu giá trị nghịch đảo hay còn được gọi là negative log likelihood (NLL).
θ^=argminθ−∑i=1Nlogp(xi|θ)
Khi này NLL và việc tối ưu cross entropy trở nên tương đương do:
θ^=argminθ−∑i=1Nlogq(xi|θ)=argminθ−∑x∈Xp(x)logq(x|θ)=argminθH(p,q)
Trong công thức trên ta thêm p(x) do p(x) đại diện cho data đã cho trước, có thể coi như là 1 đại lượng không đổi, do vậy việc tối ưu là tương đương khi thêm 1 hẳng số.
Nhưng việc nhân các giá trị như trên có thể dễ dàng dẫn đến việc tràn số (overflow) hoặc underflow. Do đó ta chuyển công thức trên về dạng log để tránh vấn đề này.
Tuy nhiên, các optimizer thông thường sẽ chỉ hỗ trợ việc minimize một hàm loss cho trước. Do vậy thay vì tối ưu trực tiếp trên MLE, ta áp dụng log và tối ưu giá trị nghịch đảo hay còn được gọi là negative log likelihood (NLL).
θ^=argminθ−∑i=1Nlogp(xi|θ)
Khi này NLL và việc tối ưu cross entropy trở nên tương đương do:
θ^=argminθ−∑i=1Nlogq(xi|θ)=argminθ−∑x∈Xp(x)logq(x|θ)=argminθH(p,q)
Trong công thức trên ta thêm p(x) do p(x) đại diện cho data đã cho trước, có thể coi như là 1 đại lượng không đổi, do vậy việc tối ưu là tương đương khi thêm 1 hẳng số.
- NHẬN XÉT
Ta xây dựng 1 mô hình để khớp với dữ liệu cho trước nhất có thể. Ta bắt đầu với MLE sau đó chuyển sang NLL để tránh việc over/underflow. Về mặt toán học thì NLL và cross entropy là tương đương. KL-div là một hướng tiếp cận khác nhưng nhìn chung với các công thức khác nhau, ta vẫn sẽ tìm được một optimal point giống nhau.
- Mean square error (MSE)
Trong các bài toán hồi quy, ta có y= f(W,x). Và trong các vấn đề thực tế, ta thường gặp phải uncertainty và việc thông tin bị khuyết. Do đó, ta có thể mô hình bài toán thao phân bố Gaussian:
y^=f(x;θ)y∼N(y;μ=y^,σ2)p(y|x;θ)=1σ2π−−√exp(−(y−y^)22σ2)
Lúc này log likelihood trở thành việc optimize MSE.
J∇θJ=∑i=1mlogp(y|x;θ)=∑i=1mlog1σ2π−−√exp(−(y(i)−y(i)^)22σ2)=∑i=1m−log(σ2π−−√)−logexp((y(i)−y(i)^)22σ2)=∑i=1m−log(σ)−12log(2π)−(y(i)−y(i)^)22σ2=−mlog(σ)−m2log(2π)−∑i=1m(y(i)−y(i)^)22σ2=−mlog(σ)−m2log(2π)−∑i=1m∥y(i)−y(i)^∥22σ2=−∇θ∑i=1m∥y(i)−y(i)^∥22σ2
Many cost functions in deep learning including the MSE, can be dervied from the MLE
Đăng ký:
Nhận xét (Atom)