Thứ Năm, 24 tháng 1, 2019
Thứ Bảy, 19 tháng 1, 2019
Semantic Segmentation
Đầu tiên ta nhắc lại về segmentation. Với segmentation, đầu vào là ảnh và đầu ra là các đường bao ứng với các vật thể và phân tách các vật thể trong ảnh.



Còn semantic segmentation, ta cần hiểu ảnh đầu vào ở mức ngữ nghĩa sâu hơn không chỉ là các đường bao vật thể.

Ví dụ với ứng dụng cho việc image captioning, với ảnh góc trên bên phải, ta có:
"Two men riding on a bike in front of a building on the road. And
there is a car."
Rõ ràng việc ngữ nghĩa (semantic) là công việc khó hơn và đòi hỏi kỹ thuật phức tạp hơn việc chỉ segmentation đơn thuần. Nhưng tiềm năng của semantic segmentation lại lớn hơn nhiều, khi mà ta có thể hiểu được toàn bộ bức ảnh và áp dụng vào các mảng khác nhau như y tế, giao thông ...
Về cơ bản, semantic segmentation có thể hiểu như:
- Phụ thuộc vào CRF (Conditional Random Field)
- Thực hiện ở mức pixel hoặc superpixel
- Phân tích sự liên quan giữa các pixel gần nhau
- Sử dụng sự liên quan giữa các label gần nhau
Để hiểu 4 điều trên, ta hãy nhìn vào 1 ví dụ:
- Các pixels gần nhau thường có xác suất có cùng label
- Các pixels có cùng màu thường có xác suất có cùng label
- Pixels phía trên pixels "chair" thường có xác suất là pixel "person" thay vì "building"
Vậy CRF là một mô hình dựa vào xác suất để có thể đưa ra các dự đoán về các pixels trên 1 ảnh.
Định nghĩa của superpixel là:
Định nghĩa của superpixel là:
The concept of superpixel was first introduced by Xiaofeng Ren and Jitendra Malik in 2003. Superpixel is a group of connected pixels with similar colors or gray levels. Superpixel segmentation is dividing an image into hundreds of non-overlapping superpixels. Instead of working with just pixels, Ren and Malik use superpixels to do image segmentation.
There are two major advantages for using superpixels.
- you can compute features on more meaningful regions.
- you can reduce the input entities for the subsequnt algorithms.
Superpixel segmentation have been applied to many computer vision tasks, such as sematic segmentation, visual tracking, image classification, and so on.
Thứ Hai, 14 tháng 1, 2019
[Natural Language Processing] NLTK experiences
- Tách từ

- Chuẩn hóa

- Stemming

- Lemmatizing

- Tách câu
NLTK không chỉ hỗ trợ việc tách token trong 1 câu mà còn hỗ trợ việc tách các câu riêng rẽ trong 1 đoạn văn bản. Ví dụ với đoạn văn sau đây:
Khi đó ta không thể dùng text12.split('TOKEN') để tách các câu được vì kết thúc câu có thể là dấu chấm câu, cảm thán, dấu hỏi ... NLTK có bộ tách câu.







- POS tagging
POS tagging là để ta có thể gắn các thành phần trong câu với vai trò tương ứng của chúng ví dụ như chủ ngữ, vị ngữ hay tính từ, tân ngữ ... Tuy nhiên, để gắn nhãn một cách chính xác, ta định nghĩa thêm nhiều vai trò khác ví dụ như mạo từ, liên từ, động từ khuyết thiếu ...
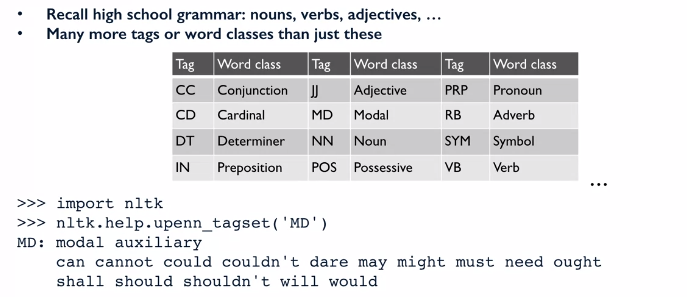
NLTK có bộ POS tagger cho phép ra thực hiện việc này.

Ta có thể thấy từ đầu ra này, ta có thể có các nhóm khác nhau như danh từ, động từ, tính từ ... cho việc xử lý sau đó.
- Parsing Sentence Structure
Khi phân tích cú pháp một câu, ta sẽ luôn có thành phần NP và VP, VP có thể chứa thêm các NP như câu dưới đây, đây là một ví dụ rất đơn giản và cấu trúc dễ phân tích.

NLTK cũng hỗ trợ bộ ChartParser để ta có thể xem được cây cú pháp của 1 câu. Tuy nhiên đôi khi cấu trúc không rõ ràng như sau: I saw the man with a telescope, lúc này này không biết telescope được cầm bởi tôi hay là the man - người đàn ông..

Ta cũng có thể load một cây cú pháp có sẵn và áp dụng vào cho 1 câu.

Tuy nhiên cách làm này không hiệu quả trong thực tế, do đó ta sẽ cần train mô hình để có thể thực hiện việc phân tích cú pháp một cách cụ thể và chính xác.
Chủ Nhật, 6 tháng 1, 2019
Ôi, tiến sĩ Việt! - petrotimes.vn 2014
Hiện Việt Nam có hơn 24.000 tiến sĩ, nhưng hằng năm số lượng các bài báo được đăng trên các tạp chí khoa học danh tiếng trên thế giới thì chỉ đếm trên đầu ngón tay, thấp nhất so với các nước trong khu vực, thậm chí còn ít hơn số lượng các bài báo khoa học của một trường đại học của Nhật Bản hoặc Hàn Quốc.
Số giáo sư, tiến sĩ của xứ ta nhiều nhất Đông Nam Á nhưng không có trường đại học nào của chúng ta được đứng trong bảng xếp hạng 500 trường đại học hàng đầu thế giới.
Như mọi người đều biết, là đầu vào của cao học, tiến sĩ, ngoài chuyên ngành học ra thì ngoại ngữ là điều kiện bắt buộc. Nếu như vậy thì trình độ ngoại ngữ của các ứng sinh phải đạt ở một trình độ đủ để nghe giảng. Nhưng mới đây, kỳ thi tốt nghiệp THPT, Bộ Giáo dục và Đào tạo (GD&ĐT) đã quyết định loại môn ngoại ngữ ra khỏi môn thi bắt buộc mà là môn thi tự chọn.
Theo lý giải của Bộ trưởng Bộ GD&ĐT khi trả lời chất vấn tại kỳ họp Quốc hội thứ 7 khóa XIII là do chất lượng dạy và học ngoại ngữ ở cấp THPT không đạt yêu cầu, chất lượng thấp, đội ngũ giáo viên không đủ chuẩn, học sinh chủ yếu được dạy về ngữ pháp cho nên tốt nghiệp THPT vẫn không nói được, có nói cũng không ai hiểu. Tóm lại là việc dạy và học ngoại ngữ ở THPT là thất bại.
Việc dạy và học ngoại ngữ trong các trường đại học cũng không mấy khả quan, chỉ trừ những trường chuyên ngữ, hoặc ngoại giao, còn hầu hết trình độ ngoại ngữ của cử nhân Việt Nam rất kém.
Trình độ ngoại ngữ như vậy, thế nhưng ai mà đi thi cao học hầu hết là đỗ, nếu không may có trượt môn ngoại ngữ thì có cơ sở còn linh động cho nợ đầu vào, vậy thử hỏi rằng, những mảnh bằng thạc sĩ, tiến sĩ liệu có mấy giá trị về khoa học, tri thức? Có những vấn đề về khoa học, học thuật mà nước ngoài người ta đã giải quyết từ lâu, nhưng do “mù” ngoại ngữ nên vẫn tưởng đề tài của mình nghiên cứu là mới.
Cũng không đâu như ta, khi quy hoạch, bổ nhiệm, đề bạt cán bộ, từ cấp phòng trở lên thì ngoài rất nhiều tiêu chí như phẩm chất, năng lực, trình độ chuyên môn, bắt buộc phải có chứng chỉ ngoại ngữ. Thế là dù một chữ nước ngoài bẻ đôi không biết nhưng cũng phải cố xoay cho bằng được chứng chỉ ngoại ngữ dởm giá vài ba triệu của những trung tâm ngoại ngữ cấp tốc mọc nhan nhản ngoài phố, trên mạng, cần bao nhiêu, trình độ gì cũng có, miễn là nộp mấy ảnh chân dung, kèm theo vài dòng thông tin cá nhân.
Rất nhiều công chức Nhà nước từ lúc trẻ đến khi về hưu, mỗi năm một lần khai bổ sung lý lịch thì có một mục không thay đổi đó là: Trình độ ngoại ngữ thường ghi là: Anh văn bằng B. Tại sao lại không phải là trình độ A, trình độ C. Vì B là mức trung bình, nếu bằng A thì mọi người nghĩ mình dốt, còn bằng C thì lại sợ mọi người nghĩ mình khai man cho nên bằng B là an toàn nhất và chỉ cần khai như vậy là xong chứ có bao giờ tổ chức kiểm tra là cái chứng chỉ ngoại ngữ ấy thật hay là giả, trình độ đến đâu.
Hiện nay ở ta, bất cứ ai cũng có thể ghi danh để dự thi tiếng Anh IELTS, đương nhiên phải kèm theo một số phí ghi danh để lấy chứng chỉ ngoại ngữ tiếng Anh do Hội đồng Anh tổ chức mỗi năm 2 kỳ với nội dung thi viết, kiểm tra kỹ năng đọc hiểu và nghe hiểu do giáo viên bản ngữ trực tiếp kiểm tra. Nếu đạt ở trình độ nào thì được cấp chứng chỉ tương đương. Chứng chỉ đó có giá trị toàn cầu, bởi những thông tin rất cụ thể, tỉ mỉ, có ảnh được in trực tiếp vào chứng chỉ, không phải ảnh dán như của ta, mỗi chứng chỉ có một mã số, mã vạch riêng, thông tin được kết nối và lưu giữ tại một trung tâm ở nước ngoài, thành thử không bao giờ có thể làm giả hoặc mua được chứng chỉ ngoại ngữ kiểu này. Mỗi chứng chỉ ngoại ngữ chỉ có giá trị trong 2 năm, quá 2 năm thì không thể mang chứng chỉ đó để đi xin việc, nếu công ty đó yêu cầu ngoại ngữ và buộc phải thi lại, nếu trình độ tiến bộ thì được cấp chứng chỉ cao hơn, nếu không đạt thì sẽ được cấp chứng chỉ có số chấm thấp hơn, chứ không có chuyện như ở Việt Nam, cứ cả đời bằng B là yên tâm, khỏi phải học nữa.
Chính vì trình độ ngoại ngữ như vậy, cho nên dẫn đến hậu quả là chất lượng của các luận án thạc sĩ, tiến sĩ rất có vấn đề vì người học đâu có biết ngoại ngữ mà đọc tài liệu tham khảo nước ngoài để cập nhật những thông tin có thể nói là thay đổi hằng ngày hằng giờ như hiện nay.
Cũng không đâu như ở ta lại có cả dịch vụ viết thuê luận án thạc sĩ, tiến sĩ. Chỉ cần cung cấp nội dung đề tài và một số tiền không nhỏ sẽ có người viết thuê ngay. Cũng từ đó sinh ra tệ đạo luận văn, luận án thạc sĩ, tiến sĩ, ít thì cũng mươi, mười lăm trang, nhiều thì vài chục trang, chép y xì của những luận án khác cùng chuyên ngành. Bản thân người làm luận án chưa chắc đã cố ý đạo luận văn của người khác, nhưng vì đi thuê người viết thì họ chép của ai, họ đưa cái gì vào thì đâu có kiểm soát được và tình trạng đạo luận văn, luận án không chỉ còn là cá biệt nữa. Đáng buồn hơn, việc đạo này còn xảy ra đối với cả những vị giữ chức vụ phụ trách trường đại học có truyền thống và danh tiếng nhất nhì cả nước, mà báo chí đã từng lên tiếng.
Đạo luận án, mua luận án trong nước còn chưa đã, có quan chức ở địa phương còn chơi sang, bỏ tiền của Nhà nước để mua bằng tiến sĩ rởm của trung tâm đào tạo đại học có tên là Đại học Nam Thái Bình Dương thì thật là hết lời bình.
Cũng không đâu như ở Việt Nam mà tỷ lệ tiến sĩ trong hàng ngũ lãnh đạo lại cao đến vậy. Nếu tính từ hàm thứ trưởng trở lên, số người có trình độ tiến sĩ ở Việt Nam cao gấp 5 lần Nhật Bản.
Theo con số của Bộ GD&ĐT, đến năm 2013 có 633 tiến sĩ là giảng viên các trường cao đẳng, 8.519 tiến sĩ là giảng viên các trường đại học. Vậy 15.000 tiến sĩ còn lại ở đâu? Chắc chắn số còn lại là các vị lãnh đạo, công chức, làm việc tại cơ quan, doanh nghiệp Nhà nước.
Một sự thật dẫu chua xót, song cần phải nhìn thẳng đó là tình trạng “tiến sĩ hóa” hoặc “phổ cập tiến sĩ” đối với lãnh đạo và đi kèm là chất lượng của những tấm bằng tiến sĩ kiểu ấy đang rất có vấn đề. Đó là nội dung các luận án không có phát kiến, phát minh gì mới, hoặc đưa ra được những biện giải, đề xuất mang tính đột phá mà chủ yếu là tập hợp tư liệu, rồi so sánh và đưa ra một vài kiến nghị chung chung, nhất là những luận án thuộc lĩnh vực khoa học xã hội, quản lý Nhà nước... phần lớn chỉ là nâng cấp luận văn tốt nghiệp đại học mà thôi, do vậy không áp dụng được vào cuộc sống, hoặc những vấn đề đã rất cũ, giáo điều không cần thiết cho cuộc sống hiện tại, cho nên bảo vệ xong cho dù luận án được hội đồng bảo vệ chấm điểm xuất sắc cũng chỉ đút vào ngăn kéo, hoặc trưng trên giá sách cho oai vậy thôi.
Bộ GD&ĐT đã thấy được chuyện này như trả lời của Bộ trưởng Phạm Vũ Luận trong phiên chất vấn tại Quốc hội vừa rồi và sắp tới sẽ có nhiều giải pháp để nâng cao chất lượng đào tạo tiến sĩ, từ việc thi đầu vào ra sao, rồi điều kiện của các cơ sở được phép đào tạo tiến sĩ, phải có bao nhiêu tiến sĩ cơ hữu của trường mới được đào tạo tiến sĩ, rồi trình độ, năng lực của các thầy hướng dẫn, thầy phản biện, hội đồng bảo vệ...
Giải pháp đã có, nhưng nếu không làm quyết liệt, đến nơi đến chốn mà vẫn buông lỏng như thời gian qua thì sẽ lại thêm rất nhiều “tiến sĩ giấy” gia nhập tầng lớp trí thức tinh hoa của đất nước...
Như mọi người đều biết, là đầu vào của cao học, tiến sĩ, ngoài chuyên ngành học ra thì ngoại ngữ là điều kiện bắt buộc. Nếu như vậy thì trình độ ngoại ngữ của các ứng sinh phải đạt ở một trình độ đủ để nghe giảng. Nhưng mới đây, kỳ thi tốt nghiệp THPT, Bộ Giáo dục và Đào tạo (GD&ĐT) đã quyết định loại môn ngoại ngữ ra khỏi môn thi bắt buộc mà là môn thi tự chọn.
Theo lý giải của Bộ trưởng Bộ GD&ĐT khi trả lời chất vấn tại kỳ họp Quốc hội thứ 7 khóa XIII là do chất lượng dạy và học ngoại ngữ ở cấp THPT không đạt yêu cầu, chất lượng thấp, đội ngũ giáo viên không đủ chuẩn, học sinh chủ yếu được dạy về ngữ pháp cho nên tốt nghiệp THPT vẫn không nói được, có nói cũng không ai hiểu. Tóm lại là việc dạy và học ngoại ngữ ở THPT là thất bại.
Việc dạy và học ngoại ngữ trong các trường đại học cũng không mấy khả quan, chỉ trừ những trường chuyên ngữ, hoặc ngoại giao, còn hầu hết trình độ ngoại ngữ của cử nhân Việt Nam rất kém.
Trình độ ngoại ngữ như vậy, thế nhưng ai mà đi thi cao học hầu hết là đỗ, nếu không may có trượt môn ngoại ngữ thì có cơ sở còn linh động cho nợ đầu vào, vậy thử hỏi rằng, những mảnh bằng thạc sĩ, tiến sĩ liệu có mấy giá trị về khoa học, tri thức? Có những vấn đề về khoa học, học thuật mà nước ngoài người ta đã giải quyết từ lâu, nhưng do “mù” ngoại ngữ nên vẫn tưởng đề tài của mình nghiên cứu là mới.
Cũng không đâu như ta, khi quy hoạch, bổ nhiệm, đề bạt cán bộ, từ cấp phòng trở lên thì ngoài rất nhiều tiêu chí như phẩm chất, năng lực, trình độ chuyên môn, bắt buộc phải có chứng chỉ ngoại ngữ. Thế là dù một chữ nước ngoài bẻ đôi không biết nhưng cũng phải cố xoay cho bằng được chứng chỉ ngoại ngữ dởm giá vài ba triệu của những trung tâm ngoại ngữ cấp tốc mọc nhan nhản ngoài phố, trên mạng, cần bao nhiêu, trình độ gì cũng có, miễn là nộp mấy ảnh chân dung, kèm theo vài dòng thông tin cá nhân.
Rất nhiều công chức Nhà nước từ lúc trẻ đến khi về hưu, mỗi năm một lần khai bổ sung lý lịch thì có một mục không thay đổi đó là: Trình độ ngoại ngữ thường ghi là: Anh văn bằng B. Tại sao lại không phải là trình độ A, trình độ C. Vì B là mức trung bình, nếu bằng A thì mọi người nghĩ mình dốt, còn bằng C thì lại sợ mọi người nghĩ mình khai man cho nên bằng B là an toàn nhất và chỉ cần khai như vậy là xong chứ có bao giờ tổ chức kiểm tra là cái chứng chỉ ngoại ngữ ấy thật hay là giả, trình độ đến đâu.
Hiện nay ở ta, bất cứ ai cũng có thể ghi danh để dự thi tiếng Anh IELTS, đương nhiên phải kèm theo một số phí ghi danh để lấy chứng chỉ ngoại ngữ tiếng Anh do Hội đồng Anh tổ chức mỗi năm 2 kỳ với nội dung thi viết, kiểm tra kỹ năng đọc hiểu và nghe hiểu do giáo viên bản ngữ trực tiếp kiểm tra. Nếu đạt ở trình độ nào thì được cấp chứng chỉ tương đương. Chứng chỉ đó có giá trị toàn cầu, bởi những thông tin rất cụ thể, tỉ mỉ, có ảnh được in trực tiếp vào chứng chỉ, không phải ảnh dán như của ta, mỗi chứng chỉ có một mã số, mã vạch riêng, thông tin được kết nối và lưu giữ tại một trung tâm ở nước ngoài, thành thử không bao giờ có thể làm giả hoặc mua được chứng chỉ ngoại ngữ kiểu này. Mỗi chứng chỉ ngoại ngữ chỉ có giá trị trong 2 năm, quá 2 năm thì không thể mang chứng chỉ đó để đi xin việc, nếu công ty đó yêu cầu ngoại ngữ và buộc phải thi lại, nếu trình độ tiến bộ thì được cấp chứng chỉ cao hơn, nếu không đạt thì sẽ được cấp chứng chỉ có số chấm thấp hơn, chứ không có chuyện như ở Việt Nam, cứ cả đời bằng B là yên tâm, khỏi phải học nữa.
Chính vì trình độ ngoại ngữ như vậy, cho nên dẫn đến hậu quả là chất lượng của các luận án thạc sĩ, tiến sĩ rất có vấn đề vì người học đâu có biết ngoại ngữ mà đọc tài liệu tham khảo nước ngoài để cập nhật những thông tin có thể nói là thay đổi hằng ngày hằng giờ như hiện nay.
Cũng không đâu như ở ta lại có cả dịch vụ viết thuê luận án thạc sĩ, tiến sĩ. Chỉ cần cung cấp nội dung đề tài và một số tiền không nhỏ sẽ có người viết thuê ngay. Cũng từ đó sinh ra tệ đạo luận văn, luận án thạc sĩ, tiến sĩ, ít thì cũng mươi, mười lăm trang, nhiều thì vài chục trang, chép y xì của những luận án khác cùng chuyên ngành. Bản thân người làm luận án chưa chắc đã cố ý đạo luận văn của người khác, nhưng vì đi thuê người viết thì họ chép của ai, họ đưa cái gì vào thì đâu có kiểm soát được và tình trạng đạo luận văn, luận án không chỉ còn là cá biệt nữa. Đáng buồn hơn, việc đạo này còn xảy ra đối với cả những vị giữ chức vụ phụ trách trường đại học có truyền thống và danh tiếng nhất nhì cả nước, mà báo chí đã từng lên tiếng.
Đạo luận án, mua luận án trong nước còn chưa đã, có quan chức ở địa phương còn chơi sang, bỏ tiền của Nhà nước để mua bằng tiến sĩ rởm của trung tâm đào tạo đại học có tên là Đại học Nam Thái Bình Dương thì thật là hết lời bình.
Cũng không đâu như ở Việt Nam mà tỷ lệ tiến sĩ trong hàng ngũ lãnh đạo lại cao đến vậy. Nếu tính từ hàm thứ trưởng trở lên, số người có trình độ tiến sĩ ở Việt Nam cao gấp 5 lần Nhật Bản.
Theo con số của Bộ GD&ĐT, đến năm 2013 có 633 tiến sĩ là giảng viên các trường cao đẳng, 8.519 tiến sĩ là giảng viên các trường đại học. Vậy 15.000 tiến sĩ còn lại ở đâu? Chắc chắn số còn lại là các vị lãnh đạo, công chức, làm việc tại cơ quan, doanh nghiệp Nhà nước.
Một sự thật dẫu chua xót, song cần phải nhìn thẳng đó là tình trạng “tiến sĩ hóa” hoặc “phổ cập tiến sĩ” đối với lãnh đạo và đi kèm là chất lượng của những tấm bằng tiến sĩ kiểu ấy đang rất có vấn đề. Đó là nội dung các luận án không có phát kiến, phát minh gì mới, hoặc đưa ra được những biện giải, đề xuất mang tính đột phá mà chủ yếu là tập hợp tư liệu, rồi so sánh và đưa ra một vài kiến nghị chung chung, nhất là những luận án thuộc lĩnh vực khoa học xã hội, quản lý Nhà nước... phần lớn chỉ là nâng cấp luận văn tốt nghiệp đại học mà thôi, do vậy không áp dụng được vào cuộc sống, hoặc những vấn đề đã rất cũ, giáo điều không cần thiết cho cuộc sống hiện tại, cho nên bảo vệ xong cho dù luận án được hội đồng bảo vệ chấm điểm xuất sắc cũng chỉ đút vào ngăn kéo, hoặc trưng trên giá sách cho oai vậy thôi.
Bộ GD&ĐT đã thấy được chuyện này như trả lời của Bộ trưởng Phạm Vũ Luận trong phiên chất vấn tại Quốc hội vừa rồi và sắp tới sẽ có nhiều giải pháp để nâng cao chất lượng đào tạo tiến sĩ, từ việc thi đầu vào ra sao, rồi điều kiện của các cơ sở được phép đào tạo tiến sĩ, phải có bao nhiêu tiến sĩ cơ hữu của trường mới được đào tạo tiến sĩ, rồi trình độ, năng lực của các thầy hướng dẫn, thầy phản biện, hội đồng bảo vệ...
Giải pháp đã có, nhưng nếu không làm quyết liệt, đến nơi đến chốn mà vẫn buông lỏng như thời gian qua thì sẽ lại thêm rất nhiều “tiến sĩ giấy” gia nhập tầng lớp trí thức tinh hoa của đất nước...
[Python Programming] Pytorch experiences
github.com/yeulam1thienthan/-Udacity-Deep-Learning-with-Pytorch
Trong các bài toán NN, khi ta đưa đầu vào, thường là các vector, ta cần làm phẳng (flattening out) input. Ví dụ đầu vào là 1 tập 64 ảnh gray size 28x28, khi này input tensor sẽ là (64,1,28,28) với 64 là thể hiện số ảnh. 1 thể hiện độ sáng của ảnh gray từ 0 - 255, ảnh có 28 hàng và 28 cột tương ứng với 784 pixels. Thông thường, với hidden layer ngay cạnh input layer số gồm 784 units ứng với 784 features của input, do đó ta sẽ cần làm phẳng input tensor từ (64,1,28,28) thành (64,784).
Pytorch cung cấp cho ta hàm tối ưu nhất so với torch.reshape và torch.resize đó là torch.view.
Khi dùng torch.view, thay vì ta truyền thẳng các chiều của tensor như. torch.view(64,784), ta chỉ cần dùng torch.view(input.shape[0], -1). Khi này input.shape[0] là 64, và khi tham số thứ 2 là -1, pytorch sẽ tự hiểu là ta muốn reshape với số chiều thứ 2 là tích của các chiều còn lại.
Pytorch cung cấp hàm loss cross-entropy(

Ở đây ta sử dụng cross-entropy là hàm loss, và input của hàm này là đầu ra của model(images) cùng với lavel cho trước.
Pytorch cũng hỗ trợ các module cho việc tính toán back-propagation và gradient-descent. Ví dụ ta muốn train một mạng fully-connected NN với 5 epochs cho tập dữ liệu MNIST, hàm loss.backward() sẽ thực hiện đạo hàm, và việc update các ma trận W sẽ được thực hiện bởi optimizer.step().









- Miscelaneous
Trong các bài toán NN, khi ta đưa đầu vào, thường là các vector, ta cần làm phẳng (flattening out) input. Ví dụ đầu vào là 1 tập 64 ảnh gray size 28x28, khi này input tensor sẽ là (64,1,28,28) với 64 là thể hiện số ảnh. 1 thể hiện độ sáng của ảnh gray từ 0 - 255, ảnh có 28 hàng và 28 cột tương ứng với 784 pixels. Thông thường, với hidden layer ngay cạnh input layer số gồm 784 units ứng với 784 features của input, do đó ta sẽ cần làm phẳng input tensor từ (64,1,28,28) thành (64,784).
Pytorch cung cấp cho ta hàm tối ưu nhất so với torch.reshape và torch.resize đó là torch.view.
Khi dùng torch.view, thay vì ta truyền thẳng các chiều của tensor như. torch.view(64,784), ta chỉ cần dùng torch.view(input.shape[0], -1). Khi này input.shape[0] là 64, và khi tham số thứ 2 là -1, pytorch sẽ tự hiểu là ta muốn reshape với số chiều thứ 2 là tích của các chiều còn lại.
- Train 1 mạng NN
Pytorch cung cấp hàm loss cross-entropy(
nn.CrossEntropyLoss). Đầu vào của hàm này phải là score cho từng class thay vì xác xuất cho từng class khi ta cho đầu ra đi qua hàm soft-max. Ví dụ như sau:
Pytorch cũng hỗ trợ các module cho việc tính toán back-propagation và gradient-descent. Ví dụ ta muốn train một mạng fully-connected NN với 5 epochs cho tập dữ liệu MNIST, hàm loss.backward() sẽ thực hiện đạo hàm, và việc update các ma trận W sẽ được thực hiện bởi optimizer.step().

Khi đó, với 1 sample ngẫu nhiên từ tập dataset, ta có thể dự đoán chính xác.

- Lưu và load 1 mạng NN được train sẵn
Khi mô hình ta đã được train, ta có thể lưu các thông số của mô hình cho các dự đoán tiếp theo mà không cần train lại từ đầu, ta sẽ tìm hiểu cách để lưu và load một pre-trained model trong Pytorch.
Giả sử ta có một class Network trong fc_model, khi đó ta khởi tạo mạng NN như sau:

Cũng trong fc_model, ta gọi method train để tìm ra thông số cho mạng NN này.

Lúc này, tất cả các thông tin của mạng NN được lưu trong model.state_dict() là 1 dictionary. Ta sẽ lưu các thông số này vào 1 file checkpoint.pth sau đó load lại vào state_dict và hiển thị.


 Khi đó, ta cũng có thể tạo 1 hàm dành cho việc load model này.
Khi đó, ta cũng có thể tạo 1 hàm dành cho việc load model này.









Giả sử ta có một class Network trong fc_model, khi đó ta khởi tạo mạng NN như sau:

Ta cũng có thể xây dựng 1 mạng NN mới và thay thế các thông số của mạng đó bằng thông số của mạng NN đã được lưu, khi đó ta tạo 1 mạng mới và load các thông sô.
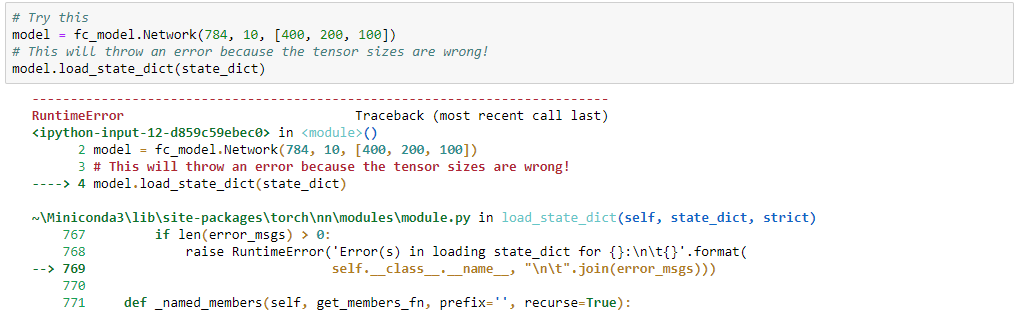
Tuy nhiên ta sẽ có lỗi do size của mạng NN được lưu và mạng NN mới khởi tạo không giống nhau, do đó ở bước thay thế các thông số của mạng mới tạo bằng các thông số của mạng lưu sẵn sẽ xảy ra lỗi.
Để tránh vấn đề này, khi lưu model, ta không chỉ lưu các parameters của model đó (W, b) mà còn nên lưu các hyperparameters bằng cách thêm các hyperparameters này khi ta lưu vào checkpoint.pth.

- Các bước xây dựng 1 mô hình NN trong Pytorch
Đầu tiên ta phải import các thư viện cần thiết của torch, ví dụ:

Tiếp theo ta load input data và preprocess các dữ liệu này.

Tiếp đó ta định nghĩa kiến trúc của mạng NN, ví dụ ta đang muốn sử dụng Transfer Learning dùng DenseNet121, lúc này ta sẽ lấy feature detection part của DenseNet121 là tự xây dựng classification part. Load mô hình DenseNet121 như sau:

Do đang thực hiện Transfer Learning, ta sẽ phải freeze các thông số của feature detection và định nghĩa là classification để thay thế, ví dụ dữ liệu ta đang có chỉ yêu cầu 2 đầu ra, mà dữ liệu của DenseNet là 1000. Sau đó ta cần định nghĩa làm loss và bộ optimizer:

Bây giờ ta đã có kiến trúc mạng như mong muốn, ta có thể train mô hình và sử dụng cho việc dự đoán. Tập dữ liệu là rất lớn do đó việc train mô hình trên GPU sẽ giúp tiết kiếm thời gian rất nhiều.

NOTE:
net.eval() will set all the layers in your model to evaluation mode. This affects layers like dropout layers that turn "off" nodes during training with some probability, but should allow every node to be "on" for evaluation. So, you should set your model to evaluation mode before testing or validating your model, and before, for example, sampling and making predictions about the likely next character in a given sequence. I'll set net.train()` (training mode) only during the training loop.- Operations
Để cộng hoặc trừ hai tensor a và b trong pytorch, ta có thể dùng a + b, torch.add(a,b), toán tử y.add_(x) sẽ trả về y = y + x.
Mọi toán tử giữa hai tensor mà có hậu tố _ như x.copy_(y hoặc x.t_() đều sẽ thay đổi giá trị x.
Khi tensor của ta chỉ có 1 phần tử, ta cần sử dụng .item() để có thể lấy giá trị trị của tensor đó.
>>> x = torch.rand(1)
>>> print(x)
tensor([0.1541])
>>> x.item()
0.15414464473724365
Pytorch cung cấp cho ta các toán tử hầu như giống hệt numpy, và ta còn có thể chuyển đổi kiểu dữ liệu từ numpy sang tensor và ngược lại.
>>> a = torch.ones(5)
>>> a
tensor([1., 1., 1., 1., 1.])
>>> b = a.numpy()
>>> b
array([1., 1., 1., 1., 1.], dtype=float32)
>>> a = torch.from_numpy(b)
>>> a
tensor([2., 2., 2., 2., 2.])
Mọi loại tensors trên CPU ngoại trừ CharTensor đều hỗ trợ việc chuyển đổi sang numpy và ngược lại.
- CNN trong Pytorch
Trong phân loại ảnh, CIFAR-10 là một tập dữ liệu nổi tiếng và thường thấy để kiểm chứng 1 mô hình. Một số hình ảnh của CIFAR-10 như sau:

Khác với MLP (Multi Layer Perceptron) khi ta sử dụng các linear và fully-connected layers, trong một CNN sẽ bao gồm.
- Convolutional layers: Là tập hợp của các bộ lọc ảnh (image filters) liên tiếp nhau ví dụ.

trong hình trên, 4 bộ lọc khác nhau tạ ra 4 ảnh đầu ra khác nhau, khi ta stack các ảnh này lại, ta tạo ra được một convolutional layer với chiều sâu (depth) là 4.

- Maxpooling layers để giảm kích thước của đầu vào, lúc này ta chỉ giữ lại các giá trị quan trọng nhất trong một cửa sổ. Ví dụ của số là 2x2 với 4 pixel, ta sẽ chỉ lấy 1 giá trị pixel quan trọng nhất, do đó chiều x và y của ảnh sẽ được giảm đi 2 lần với mỗi chiều.
- Linear và Dropout layers để tránh overfitting và sinh ra output.
- Convolutional Layer trong Pytorch
Ta định nghĩa 1 convolutional layer như sau:
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0)
trong forward, ta sử dụng layer này để xử lý input:
x = F.relu(self.conv1(x))
Giải thích các đầu vào như sau:
in_channels- Chiều sâu của dữ liệu đầu vào, ví dụ với ảnh RGB, depth = 3 và ảnh gray thì depth = 1out_channels- Số filters mà ta muốn áp dụng vào ảnh đầu vào, với số filter là K này, đầu ra của ta sẽ là K ảnh.kernel_size- Chiều dài = chiều rộng của convolutional kernel (hay filter)
Ngoài ra còn 1 số tham số khác
stride- Chiều dài trượt của kernel,strideđược set mặc định là1padding- Chiều dài ta muốn thêm vào ảnh ở đường biên, mặc địnhpaddingđược set là0.
Ngoài ra còn Pooling layer để ta có thể giảm kích thước của ảnh đầu ra sau 1 convolutional layer (tránh overfitting).
self.pool = nn.MaxPool2d(2,2)
Ở đây kernel_size = 2 và stride = 2. Ở trong hàm forward(), hàm pooling được sử dụng sau conv layer.
x = F.relu(self.conv1(x))
x = self.pool(x)
Ví dụ: Ta xây dựng 1 CNN, đầu vào là ảnh gray có kích thước 200x200 do đó nó là 1 mảng 3 chiều có chiều dài 200, rộng 200 và sâu 1.
self.conv1 = nn.Conv2d(1, 16, 2, stride=2)
Đầu vào này được xử lý bởi 16 filters, mỗi filter có chiều dài là 2 và rộng là 2, độ trượt stride = 2 và ta không muốn thêm padding vào đầu input.
Tiếp theo, đầu ra của conv1 sẽ là 16 ảnh khác nhau sau khi đi qua 16 filters. Ta định nghĩa 1 conv kế tiếp có 32 filters có chiều dài và rộng là 3, độ trượt stride = 1 và padding 1 vào đường biên.
self.conv2 = nn.Conv2d(16, 32, 3, padding=1)
Ta có thể thấy đầu vào của conv2 chính là depth của đầu ra sau conv1, vì conv1 có 16 filters nên depth sẽ cũng chính là 16.
Tiếp theo ta sẽ tìm hiểu cách tính toán size của 1 ảnh sau khi qua 1 conv layer.
Ta định nghĩa.
K- Số filter của 1 conv layerF- Chiều dài và rộng của 1filterD_in- Depth của layer trước đó, ví dụ layer trước đó là input thì depth là 3 hoặc 1 tương đương với ảnh RGB hay gray. Hoặc là 16 với ví dụ trên khi ta đang xét conv2.
Do vậy, số lượng tham số của 1 filter là F*F*D_in và ta có K filters, do đó số lượng weight sẽ là K*F*F*D_in.
Ta nhắc lại một số định nghĩa và thêm một số khác.
K- Số filter của 1 conv layerF- Chiều dài và rộng của 1filterS- Độ trượt của kernelP- PaddingW_in- Là D_in, depth của layer trước đó, ví dụ layer trước đó là input thì depth là 3 hoặc 1 tương đương với ảnh RGB hay gray. Hoặc là 16 với ví dụ trên khi ta đang xét conv2.
Ta lưu ý rằng depth của 1 conv layer sẽ luôn là số lượng filter K.
Khi đó, size của 1 ảnh khi đi qua 1 conv layer được tính là:
((W_in−F+2P)/S)+1 (*)
Ta thử làm một bài toán, dưới với ảnh đầu vào có size là 130x130 và có depth là 3 ứng với ảnh RGB.
nn.Conv2d(3, 10, 3) <--- conv1
nn.MaxPool2d(4, 4) <- maxpool1
nn.Conv2d(10, 20, 5, padding=2) <---- conv2
nn.MaxPool2d(2, 2) <- maxpool2
Khi này depth của output sẽ là depth của conv2 là 20.
Đầu tiên dựa vào công thức (*) ta có size của ảnh sau khi qua conv1.
Với conv1:
W_in = 130
F = 3
P = 0
S = 1 (by default if not specified)
W_out_conv1 = ((130-3+2x0)/1) +1 = 128 (size 128x128)
Khi qua maxpool1, size ảnh sẽ là 128/4 = 32 (size 32x32)
Với conv2:
W_in = 32
F = 5
P = 2
S = 1
W_out_con2 = ((32-5+2x2)/1) +1 = 32 (size 32x32)
Khi qua maxpool2, size ảnh là 32/2 = 16 (size 16x16)
Khi này, output cuối cùng sẽ là 20*16*16
- Data Augmentation
Khi ta train một mô hình phức tạp, gồm nhiều thông số trong mạng cần tìm, số lượng dữ liệu cần thiết là rất lớn. Do vậy, nếu số lượng dữ liệu của ta không đủ lớn, ta có thể làm gì? Trong thực tế việc tìm kiếm thêm dữ liệu đôi khi không cần thiết, ví dụ như trong ảnh dưới đây, 1 mạng neuron chưa được train tốt sẽ không phân biệt được 3 ảnh này là giống nhau.

Do đó, nếu ta muốn có thêm dữ liệu, ta chỉ cần sửa đổi một chút dữ liệu sẵn có ví dụ như ta đảo chiều ảnh, xoay ảnh hay dịch ảnh, khi đó mạng NN sẽ có thể được train tốt hơn. Kỹ thuật này được gọi là Data Augmentation như minh họa dưới đây.

Các kỹ thuật ta có thể làm bao gồm:
- Flip

Lật ảnh theo chiều dọc hoặc ngang
- Rotation

Xoay 90 độ theo chiều kim đồng hồ
- Scale/Crop

Ảnh đã được scale in 10 và 20%
- Translation

Ảnh dược dịch qua phải là dịch lên trên
- Gaussian Noise

Thêm nhiễu Gaussian
Ngoài ra còn một số kỹ thuật nâng cao khác như GAN, Style transfer, ta có thể đọc thêm từ đây.
https://medium.com/nanonets/how-to-use-deep-learning-when-you-have-limited-data-part-2-data-augmentation-c26971dc8ced
Trong Pytorch, toán tử transforms được dùng để ta có thể thực hiện data augmentation một cách cơ bản như xoay ảnh và lật ảnh, scale/crop.
Thứ Sáu, 4 tháng 1, 2019
[Machine Learning] Overfitting và Underfitting
Khi số lượng epoch quá lớn hoặc quá nhỏ như hình dưới đây, ta đều có thể gặp vấn đề.



Đồ thị tương quan giữa error trong training và testing như sau giúp ta chọn ra số lượng epoch hợp lý.

Thứ Năm, 3 tháng 1, 2019
3 nước phát triển nhất châu Á, có phải Trung Quốc, Hàn Quốc và Nhật Bản?
Trung Quốc ko hẳn là 1 nước phát triển bởi vì diện tích quá lớn, do đó trung bình thu nhập hoặc cơ sở hạ tầng là không đồng đều, tuy nhiên tiềm năng phát triển của Trung Quốc là cực kỳ lớn do diện tích khổng lồ.
Nhật Bản và Hàn Quốc có diện tích khá nhỏ và phát triển một cách mạnh mẽ, Nhật thuộc nhóm các nước G7 trong khi Hàn Quốc thuộc nhóm G20.
Nếu Nam và Bắc Hàn thống nhất, Hàn Quốc sẽ phát triển cực kỳ mạnh mẽ lí do là Triều Tiên lớn hơn Hàn Quốc và có rất nhiều tài nguyên thiên nhiên trong khi Hàn Quốc lại có công nghệ để có thể khai thác những nguồn tài nguyên này. Tuy nhiên, việc thống nhất Liên Triều khó có thể xảy ra trong tương lai gần.
Diện tích Nhật Bản đang bị thu hẹp dần do sự biến đổi khí hiệu làm dâng mực nước biển.
Nhật Bản và Hàn Quốc có diện tích khá nhỏ và phát triển một cách mạnh mẽ, Nhật thuộc nhóm các nước G7 trong khi Hàn Quốc thuộc nhóm G20.
Nếu Nam và Bắc Hàn thống nhất, Hàn Quốc sẽ phát triển cực kỳ mạnh mẽ lí do là Triều Tiên lớn hơn Hàn Quốc và có rất nhiều tài nguyên thiên nhiên trong khi Hàn Quốc lại có công nghệ để có thể khai thác những nguồn tài nguyên này. Tuy nhiên, việc thống nhất Liên Triều khó có thể xảy ra trong tương lai gần.
Diện tích Nhật Bản đang bị thu hẹp dần do sự biến đổi khí hiệu làm dâng mực nước biển.
Thứ Ba, 1 tháng 1, 2019
[Machine Learning][Deep Learning] Bidirectional RNN
Như ta đã đề cập trước đó, trong các ứng dụng, ví dụ Name Entity Recognition, cho một đầu vào x(t) ở thời điểm t, để xác định x(t) có phải là 1 entiry cần tìm hay không, ta cần phải lấy thông tin không chỉ từ các dữ liệu trước thời điểm t mà còn phải sau thời điểm t. Ví dụ trong câu sau:
He said: "Teddy Roosevelt was a great president!"
Giả sử x(3) là Teddy, x(4) là Roosevelt, khi này ta sẽ cần xem xét cả các dữ liệu đằng sau để đưa ra quyết định x(3) và x(4) có phải entity cần tìm hay không.
Mô hình BRNN được cho bởi hình dưới đây:
 Lúc này , thay vì chỉ có 1 đường forward, ta sẽ có thêm 1 đường backward, với mỗi giá trị ví dụ để tính toán output y3, tất cả các giá trị input xi đều sẽ tham gia. Các block trong mạng có thể là GRU block hoặc LSTM block.
Lúc này , thay vì chỉ có 1 đường forward, ta sẽ có thêm 1 đường backward, với mỗi giá trị ví dụ để tính toán output y3, tất cả các giá trị input xi đều sẽ tham gia. Các block trong mạng có thể là GRU block hoặc LSTM block.
Tuy nhiên, một nhược điểm của BRNN là ta chỉ có thể áp dụng mô hình này nếu toàn bộ tập dữ liệu đầu vafolaf biết trước, do đó các ứng dụng yêu cầu đáp ứng real-time có thể sẽ bị hạn chế.
Ví dụ như trong ứng dụng Speech Recognition, người dùng phải nói hết câu thì hệ thống mới có thể thực hiện.
Dù vậy, trong các ứng dụng về NLP, hầu hết các input là các corpus nên ta có thể sử dụng BRNN.
He said: "Teddy Roosevelt was a great president!"
Giả sử x(3) là Teddy, x(4) là Roosevelt, khi này ta sẽ cần xem xét cả các dữ liệu đằng sau để đưa ra quyết định x(3) và x(4) có phải entity cần tìm hay không.
Mô hình BRNN được cho bởi hình dưới đây:

Tuy nhiên, một nhược điểm của BRNN là ta chỉ có thể áp dụng mô hình này nếu toàn bộ tập dữ liệu đầu vafolaf biết trước, do đó các ứng dụng yêu cầu đáp ứng real-time có thể sẽ bị hạn chế.
Ví dụ như trong ứng dụng Speech Recognition, người dùng phải nói hết câu thì hệ thống mới có thể thực hiện.
Dù vậy, trong các ứng dụng về NLP, hầu hết các input là các corpus nên ta có thể sử dụng BRNN.
[Machine Learning][Deep Learning] Kiến trúc Long Short Term Memory (LSTM) trong RNN
Trong kiến trúc LSTM, c<t> và a<t> sẽ không tương đương nữa, lúc này LSTM sẽ gồm 3 gates Γu, Γf và Γo.



Mỗi gate đều được tính toán từ a<t-1> và x<t>, sơ đồ của 1 unit được mô tả như hình dưới đây.

Khi này, dựa vào các giá trị của các gate, ta cũng có thể sử dụng những feature xa trong 1 sequence hoặc giải quyết được vanishing/exploding gradient. LSTM là một mô hình tổng quát hơn và ra đời trước GRU rất lâu. Ta có thể thấy GRU là mô hình đơn giản hơn LSTM nhiều do đó ta có thể xây dựng được các hệ thống lớn hơn, tuy nhiên LSTM lại có performance cao do nó có 3 gates thay vì 2 gates của GRU.
Đăng ký:
Bài đăng (Atom)